 Spark 9 in Chennai, July 4-5. A 36-hour agentic AI hackathon with 5 enterprise AI tracks!
Spark 9 in Chennai, July 4-5. A 36-hour agentic AI hackathon with 5 enterprise AI tracks!
Home / Blog / Make your RAG better: A Simple Yet Powerful AI Agentic Framework
Make your RAG better: A Simple Yet Powerful AI Agentic Framework
Vithushan Sylvester
Chief Architect
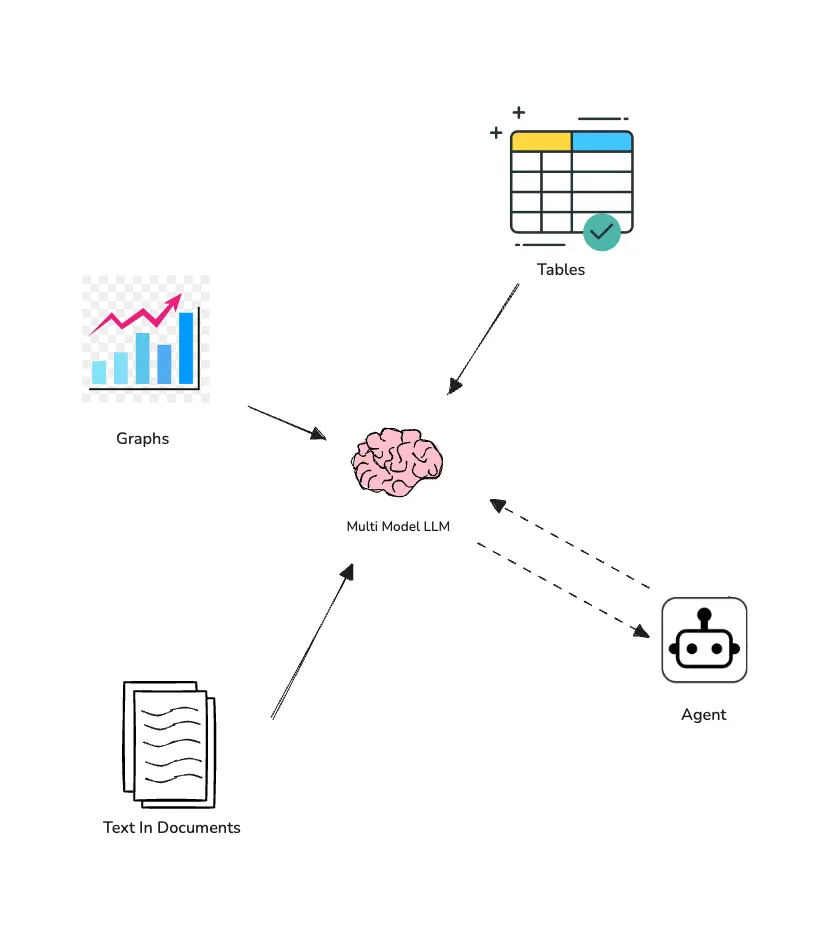


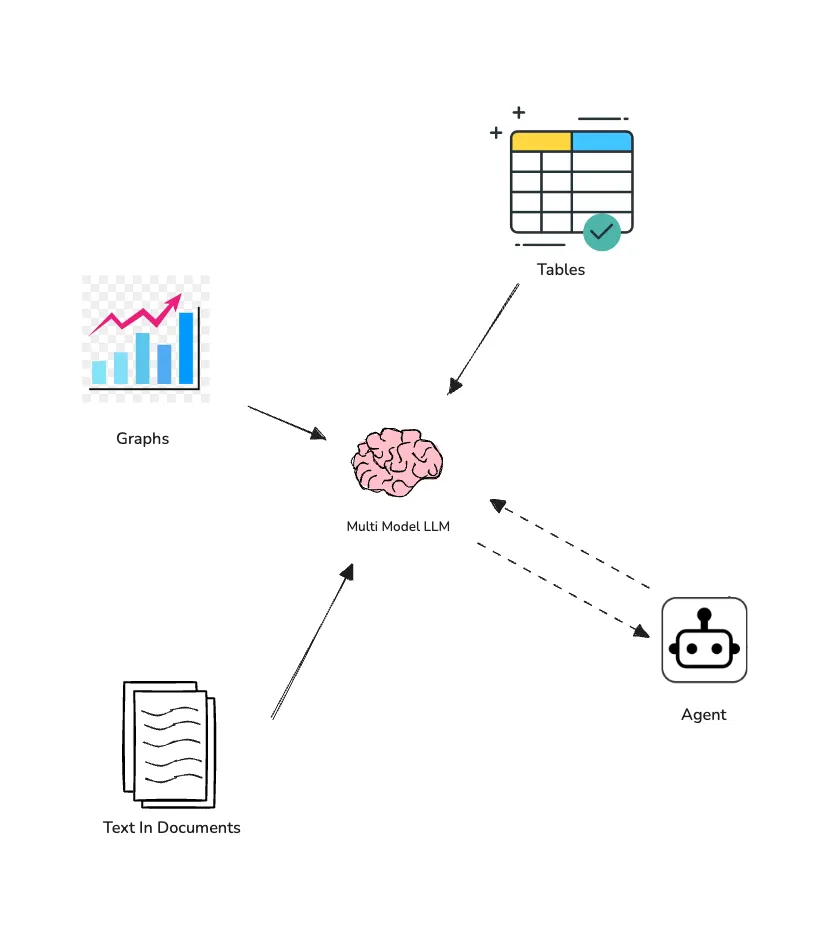
Retrieval-Augmented Generation (RAG) is a key part of modern AI systems, but many of them don’t do a great job of handling different types of documents, especially images, scanned documents, and tabular formats. Most RAG setups are designed for clean text, which means they often miss out on all the cool stuff in less structured formats.
This article introduces a super-simple yet super powerful framework that’s perfect for filling that gap. It lets your RAG system parse, understand, and reason over all sorts of complex document types, as well as plain text. And guess what? This approach includes an AI Agent in the process, which brings all the other awesome benefits from the agentic world, like memory, reasoning, tools, and more!
 In this article, we’ll show you a step-by-step guide to making your RAG pipeline even better. We’ll talk about how to improve how you parse, vectorize, and find information with .
In this article, we’ll show you a step-by-step guide to making your RAG pipeline even better. We’ll talk about how to improve how you parse, vectorize, and find information with .
Before we start, Here is a small demonstration on how this works.
Parsing
The pipeline starts with parsing that can handle not just plain text documents, but also images, tables, charts, and more.
It’s designed to work with real world documents like contracts, reports, invoices, and research papers which often have embedded charts, tables, and scanned pages.
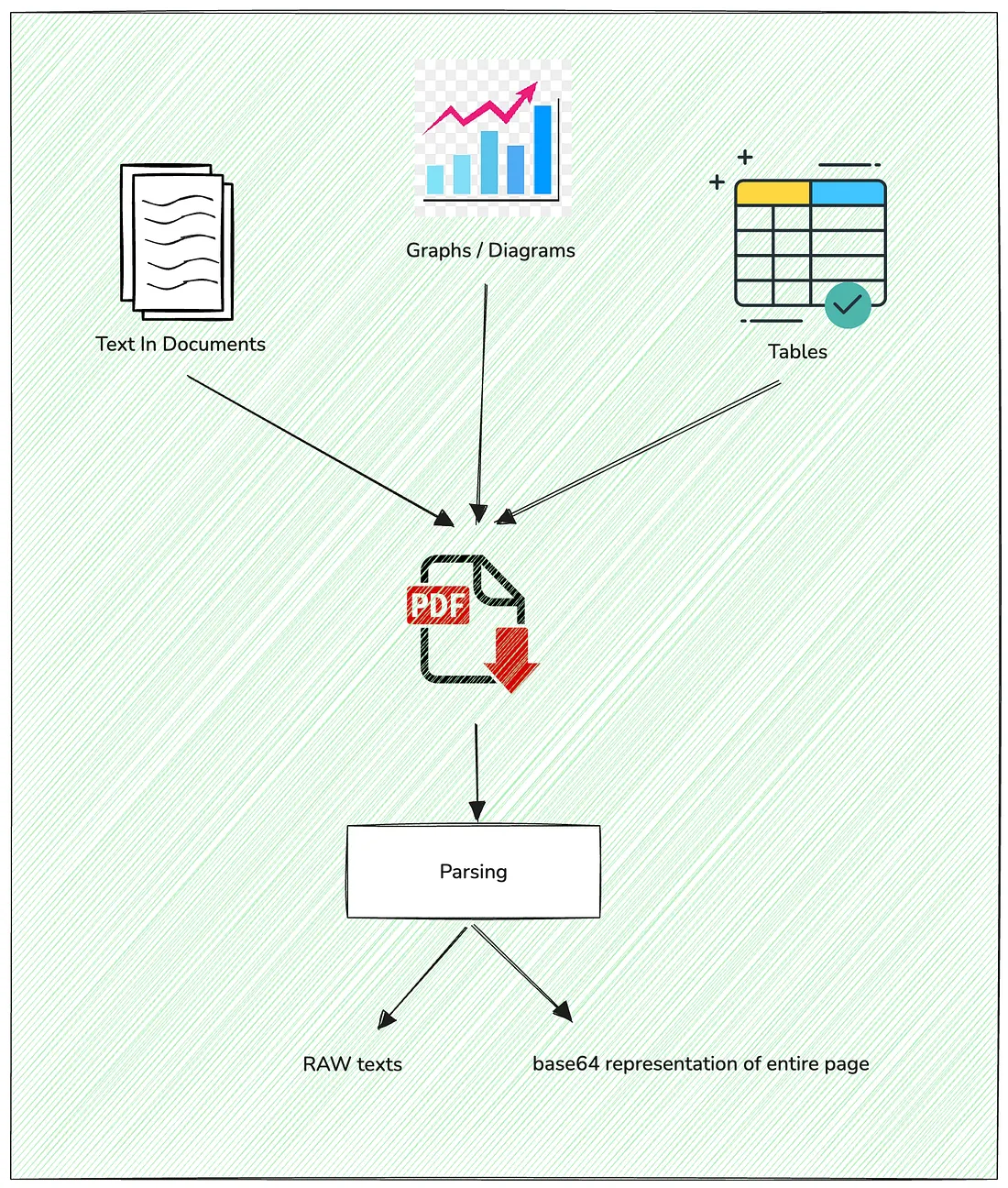 Here’s what you give it as input: a document with diagrams, graphs, tables, and raw text.
Here’s what you give it as input: a document with diagrams, graphs, tables, and raw text.
And here’s what it gives you back:
Raw text: Extracted using OCR and NLP techniques.
Base64 representations: Captures the whole page image, including the layout and visuals important for scanned and image-heavy documents.
This dual-format parsing makes sure that any AI components downstream don’t miss any important contextual or visual clues.
Vectorization — Embedding with Visual Awareness
Now that we’ve parsed the information, the next step is to convert it into vector chunks.
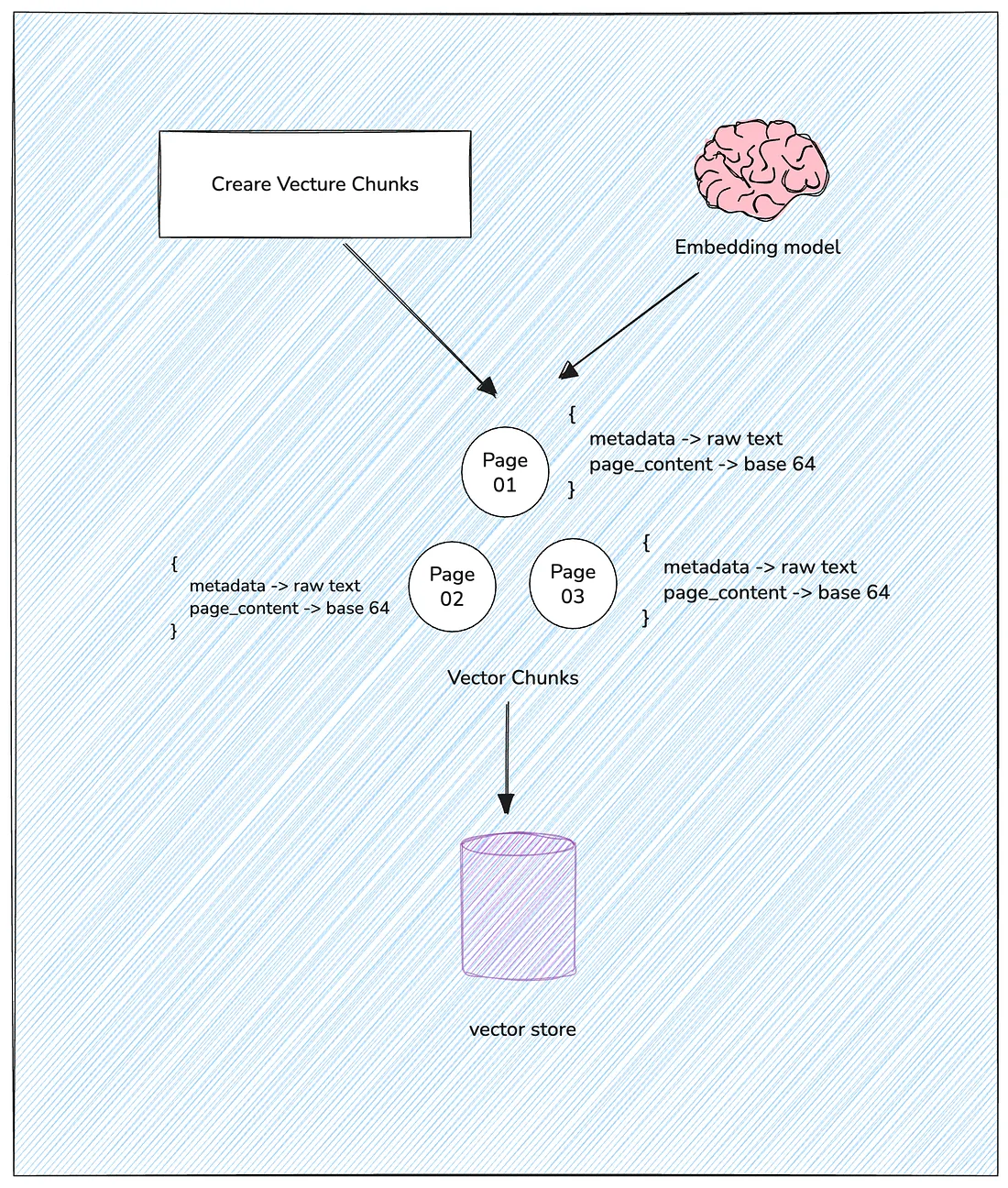 Each page is broken down into chunks, which include:
Each page is broken down into chunks, which include:
Textual metadata and raw content, which allows us to retrieve information from multiple sources later.
A visual representation in Base64, covers Scanned images and tables are transformed into meaningful embeddings that keep their structure and purpose
By including visual context, this step makes our RAG capable of answering questions based on visual layouts or tabular semantics, not just narrative text.
For this particular case, we used an OpenAI embedding model to validate our framework. However, we believe that any embedding model with good performance should produce similar results.
Retrieval
The retrieval is a crucial part of this framework, as it’s where the agent gets to play.
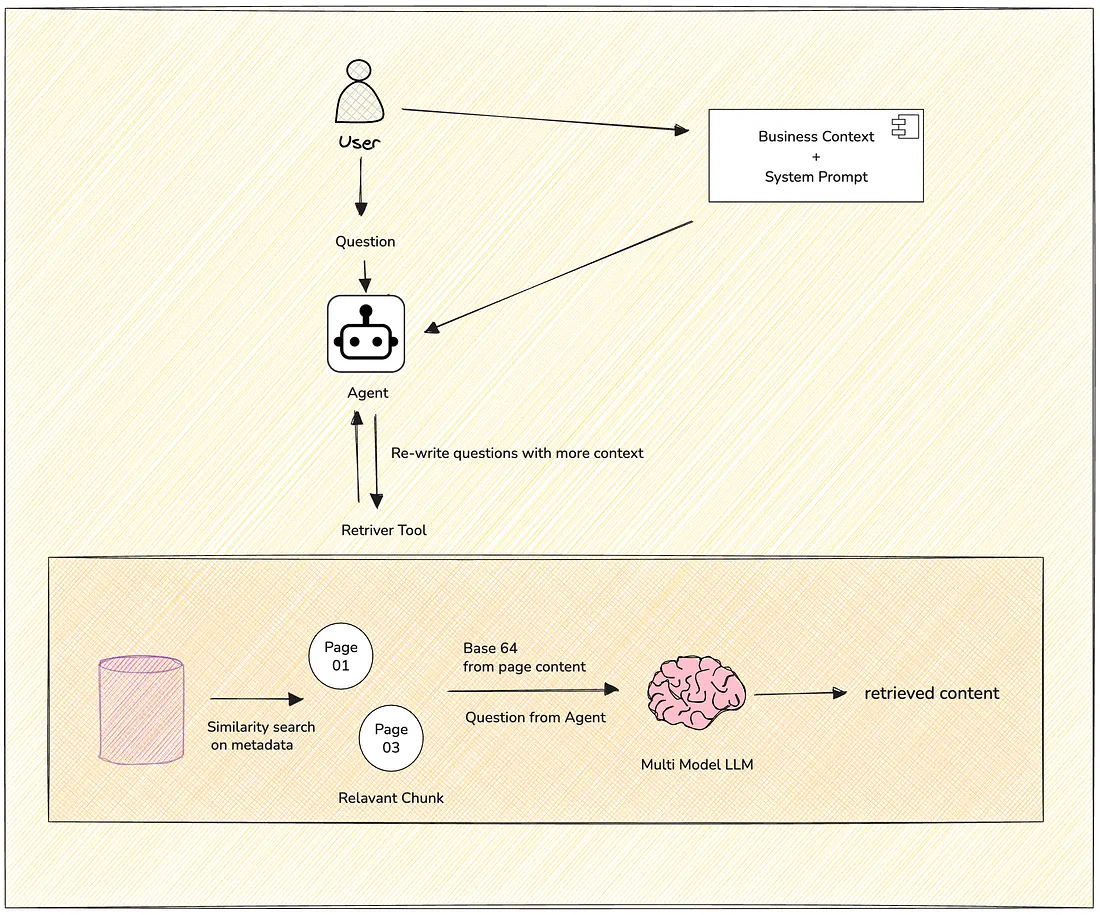 Since this is an agentic process, the agent will receive instructions (system prompt). It’s always a good idea to include some background information about the business as well (business context). This helps the agent understand the language of your business.
Since this is an agentic process, the agent will receive instructions (system prompt). It’s always a good idea to include some background information about the business as well (business context). This helps the agent understand the language of your business.
When a user asks a question, the agent will use both the business context and the system prompt to rewrite and improve the query and that question will be given to a “retriever”.
The “retriever” searches through metadata and content to find the most relevant textual part whether it’s in a table in a scanned form, a graph, or a paragraph. Then, we use a multi-modal LLM here which processes the retrieved Base64-encoded pages (as an image) and generates the summary of findings.
Once, the relevant information are there, agent will get back to the user with answers or any followup questions. Here, the “retriever” is used as a tool for the agent, which allows the agent to go on multiple iterations and makes this more accurate.
Key take-aways
This tool is especially good at handling different types of documents, like images, scanned documents, and tables. Most RAG systems struggle with this.
It uses both text and visual information to understand things better.
It adds context and can rewrite queries to improve the results.
Multi model capability helps to understand any visual data better.
Agents brings the advantage of tools, memory, reasoning, etc.
Final Thoughts
If your AI needs to work with real-world documents often messy, scanned, or full of images and tables this is the solution for you. No more ignored diagrams. No more misread tables. No more discarded scanned PDFs.
Just a heads up, this is just the basic structure of the framework that demonstrate the architecture. You can always make more improvements at each level to make it even better. For instance, you can tweak the search feature in the vector store using different patterns.
Code repository: https://github.com/vithushanms/agentic-rag



