 Spark 9 in Chennai, July 4-5. A 36-hour agentic AI hackathon with 5 enterprise AI tracks!
Spark 9 in Chennai, July 4-5. A 36-hour agentic AI hackathon with 5 enterprise AI tracks!
Home / Blog / Observing the Agent
Observing the Agent
Prashant Bista


“A 2025 study analyzing agentic LLM systems found that 79% of the non‑deterministic execution flows of AI agents are a major challenge, making observability not just useful, but essential.” AI Agents are supposed to follow instructions, but somehow end up booking flights, rewriting emails, and hallucinating facts along the way. As agents grow more complex and autonomous, understanding what they think, decide, and do becomes critical. That’s where agent observability tools come in. They help trace the mess, debug behavior, and bring the agent to the right path.
What is Agent Observability?
“A 2025 study analyzing agentic LLM systems found that 79% of the non‑deterministic execution flows of AI agents are a major challenge, making observability not just useful, but essential.” AI Agents are supposed to follow instructions, but somehow end up booking flights, rewriting emails, and hallucinating facts along the way. As agents grow more complex and autonomous, understanding what they think, decide, and do becomes critical. That’s where agent observability tools come in. They help trace the mess, debug behavior, and bring the agent to the right path.
Key Tasks Enabled by Agent Observability Tools
Agent observability tools play a critical role in monitoring, debugging, and optimizing language model-based applications. These tools allow developers to trace token usage, analyze associated costs, and visualize the flow of agent execution in real-time. In this section, we will discuss the tasks that the agent observability tools enable users to do.
1. Tracing Input and Output Tokens with Cost
Observability Tools offer comprehensive capabilities for tracking the usage and cost associated with an agent’s interactions. Specifically, they capture the exact number of tokens consumed by the agent for both input (comprising system-generated and user-provided prompts) and output (the agent’s generated responses). Furthermore, these tools meticulously record the financial expenditure linked to these tokens, leveraging the current pricing models established by the respective Large Language Model (LLM) provider. This granular data empowers developers to gain deep insights into various aspects of agent performance. They can effectively monitor the verbosity or conciseness of the agent’s interactions, identify opportunities to optimize prompts for enhanced cost efficiency, and accurately calculate both the per-run and cumulative token expenses, thereby ensuring transparent and controllable operational costs.
2. Cost Analysis of Custom Models
When leveraging custom models, tracking and analyzing their usage cost is important, particularly when these models are not pre-integrated into an existing observability platform. To achieve comprehensive oversight, these new models can be seamlessly integrated with robust observability platforms. This integration should include a detailed breakdown of associated costs, separating expenses for both input and output tokens. Such granular visibility empowers developers with a transparent view of usage expenditures, facilitates the implementation of custom pricing rules for models not natively supported by the platform, and enables crucial cost-performance comparisons across diverse models. This comprehensive data ultimately leads to more informed budgeting strategies and optimized model selection decisions.
3. Latency Incurred in Each Step
Latency tracking is all about measuring how long each step takes when your AI agent is doing its job. By tracking these delays, one can easily spot parts of the agent that are running slowly. This might be a specific tool that takes a long time to get information, or perhaps a connection to an external service (an API call) that’s experiencing delays. Pinpointing these slow spots, or “bottlenecks,” is incredibly useful because it tells us exactly where to focus our efforts to make the agent work faster and more efficiently. It helps fine-tune the agent to deliver responses as quickly as possible.
4. Tracing the Tool Calls
Agents frequently leverage external tools such as calculators, databases, or online services to perform their tasks. Monitoring the usage of these tools provides valuable insights into their frequency of use, the specific types of tools being invoked, the data inputs and outputs, and the latency of their responses. This tracking allows for a comprehensive understanding of how agents interact with and depend on external resources.
5. Human Feedback for Each Run (Annotations)
Human evaluation, also called annotations, is a key feature used to gain quality insights about how an AI agent performs. It lets people manually review and give feedback on each agent run. Evaluators can add free-text comments, assign tags or categories, and mark runs with custom labels like “helpful,” “incomplete,” or “hallucinated.” They can also give scores or flag specific outputs. This helps in understanding where the agent does well or needs improvement. These evaluations are especially useful for improving models through reinforcement learning, collecting high-quality datasets, and fine-tuning models based on real user feedback.
6. Analytics Dashboards with Visual Graphs
Dashboards provide a clear, visual overview of important metrics using graphs and charts. They usually display key information such as the total number of completed runs, average and per-step delays, how often failures happen, and when and how frequently the LLM is called. Other useful metrics include cost per run, token usage (both input and output), tool usage frequency, and system latency. These visualizations help teams quickly spot trends, identify problems, and generate reports for stakeholders or management. Also, users can create their own custom dashboard to fulfill their own needs.
7. Prompt Engineering with Playground
This interactive feature allows users to experiment with different versions of prompts and immediately see how those changes affect the output. Users can edit and re-run prompts, compare multiple phrasings side by side, and analyze the results produced by each version. This makes it easier to evaluate how prompt changes impact the quality, consistency, and accuracy of responses. It’s a powerful tool for improving prompt design and optimizing agent performance.
8. Prompt Versioning and Reusability
Beyond just experimenting, users can also save effective prompt variations for future use. This feature tracks how prompts are revised over time, the types of outputs they produce, and which versions have been marked as successful. It enables users to build a library of best-practice prompts and supports version control, making it easier to reuse and refine prompts systematically.
9. Evaluation of Runs Using LLM-as-a-Judge
This feature leverages a separate language model (LLM) to assess the quality of agent outputs automatically. It acts like a human evaluator by scoring outputs based on correctness, completeness, relevance, or other custom criteria. It can also detect issues like hallucinations or failures and provide brief explanations for the scores given. This approach allows for scalable, consistent evaluation across a large number of runs without requiring manual effort.
Tools Commonly Used for Agent Observability
To effectively monitor and evaluate the behavior of AI agents, several specialized tools have been developed. In this article, we’ll explore three widely used agent observability platforms: LangSmith, LangFuse, and Phoenix. Each of these tools offers a unique set of features designed to help developers trace agent runs, analyze token and cost usage, evaluate performance, and improve model quality. They support functions such as prompt experimentation, run comparison, error diagnosis, and integration with LLM-based evaluation methods. These tools are essential for building reliable, efficient, and transparent AI systems at scale.
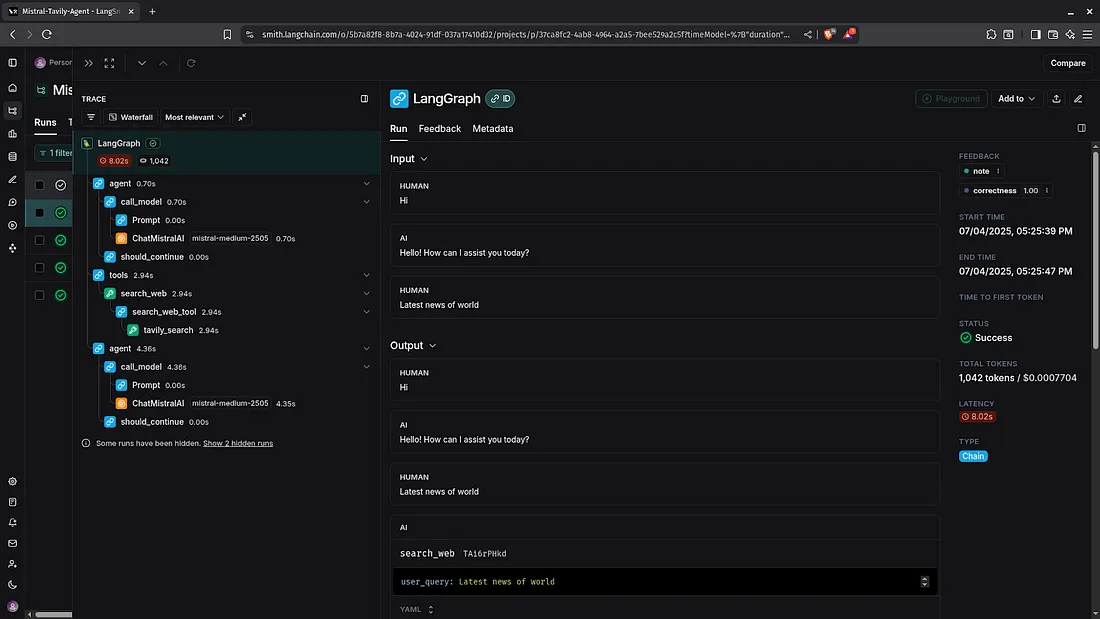
LangSmith
LangSmith is a powerful developer platform created by LangChain to observe, debug, and evaluate complex LLM applications. It offers tools to trace the entire flow of a language model’s decision-making process, particularly in agentic or chain-based systems, capturing granular metadata such as inputs, outputs, tool calls, retries, and intermediate steps. LangSmith makes it easier to understand, iterate, and improve prompt logic or tool usage by visualizing how LLM pipelines behave in real time. It is tightly integrated with LangChain but also supports custom instrumentation. With its evaluation suites and fine-grained observability, LangSmith enables rapid prototyping and production-grade monitoring of LLM workflows.
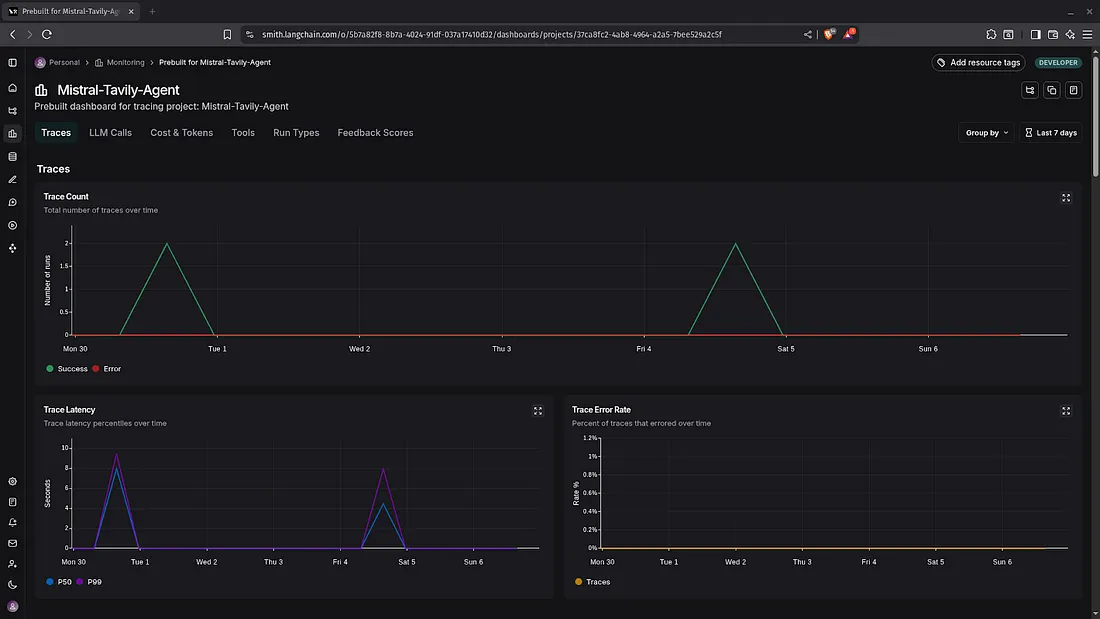
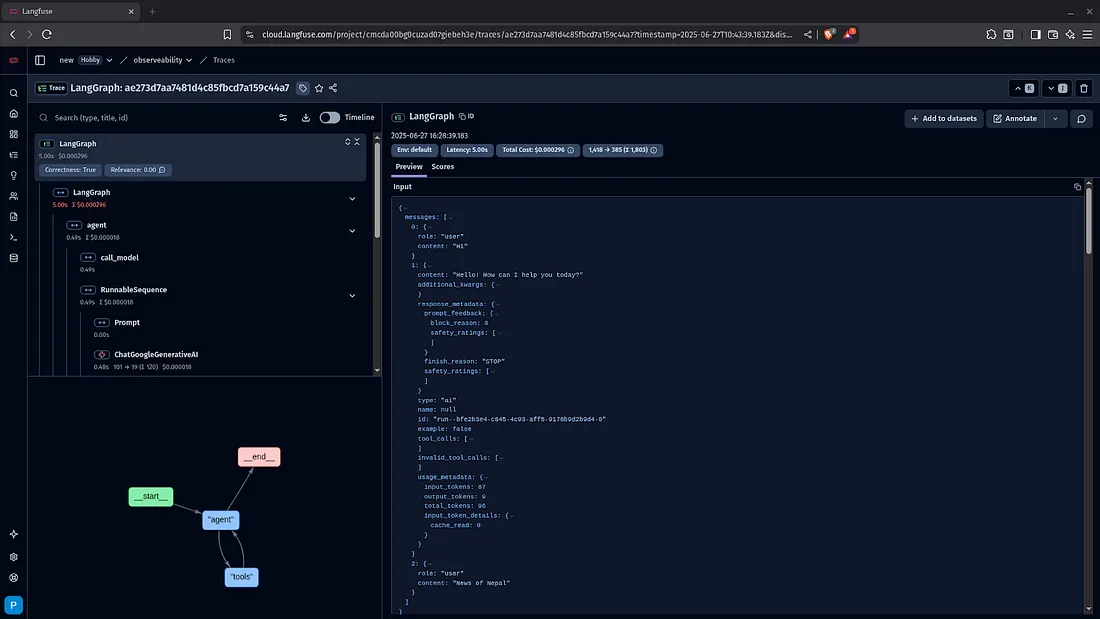
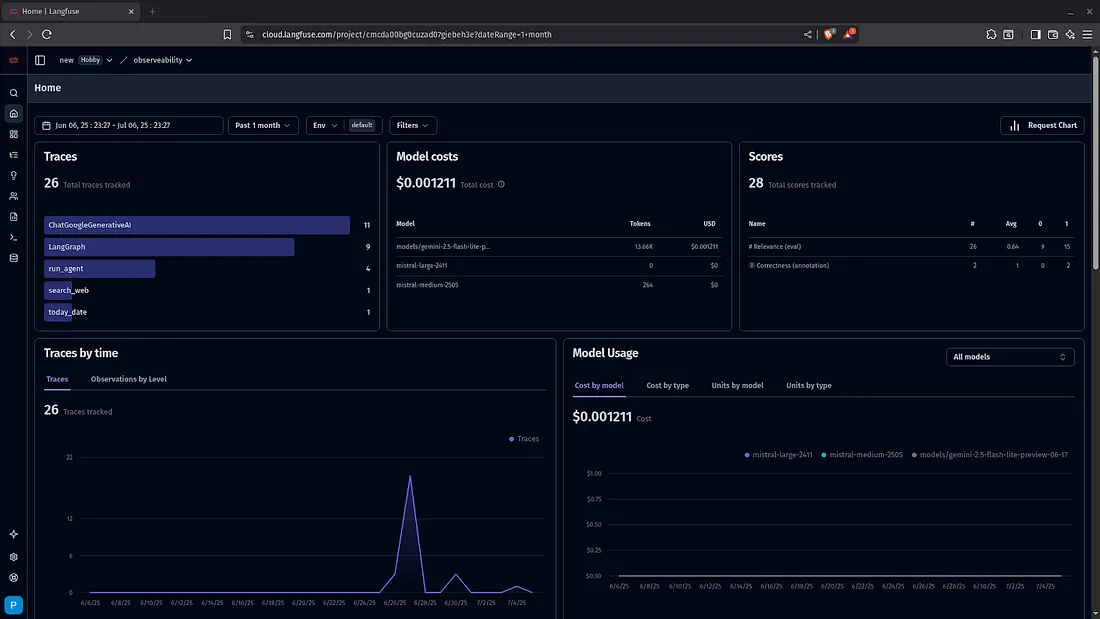
LangFuse
LangFuse is an open-source observability platform designed for monitoring and debugging LLM-based applications. It focuses on helping developers understand how their AI systems perform in production through detailed logs, traces, metrics, and custom tags. LangFuse supports both sync and async workflows and integrates easily with popular LLM frameworks. Developers can monitor latency, success/failure rates, token usage, and much more. Unlike LangSmith, LangFuse is more framework-agnostic and supports external data pipelines and custom tracing integrations. Its self-hosting option makes it especially appealing for teams with privacy or compliance needs.
Phoenix
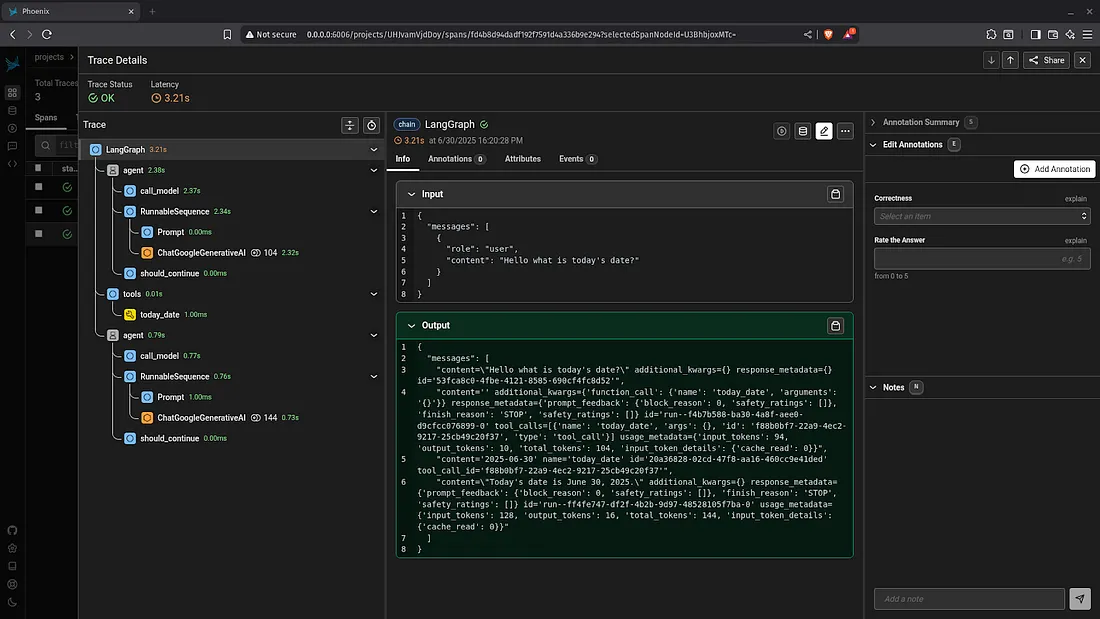
Phoenix by Arize AI is a powerful open-source tool built for deep evaluation and observability of LLM applications, especially in RAG (Retrieval-Augmented Generation) workflows. It goes beyond basic logging to provide insights into embeddings, vector search recall, hallucination risks, grounding issues, and even data quality. Phoenix integrates directly into evaluation loops and can process real and synthetic traces for more robust debugging. It’s particularly suited for production-grade LLM pipelines where traceability, data validation, and model performance metrics need to be monitored over time. Its visual dashboard helps ML teams identify what went wrong and why across multiple model runs.
Conclusion
Agent observability tools like LangSmith, LangFuse, and Phoenix are essential for building reliable, efficient, and transparent AI systems. Each platform offers powerful features from detailed token and cost tracking to advanced prompt engineering and automated evaluation, helping developers monitor performance, reduce costs, and improve output quality. While LangSmith provides a polished, hosted experience tightly integrated with LangChain, LangFuse, and Phoenix offer robust open-source alternatives with strong self-hosting capabilities and extensibility. Choosing the right tool depends on the project’s scale, budget, and customization needs. Ultimately, leveraging these observability platforms empowers teams to gain deeper insights, iterate faster, and deliver better AI-powered applications.



